Bahasa Daerah dan Chatbot AI: Tantangan Unik Pasar Indonesia
Ringkasan artikel:BahasaDaerahdanChatbotAI:TantanganUnikPasarIndonesia Indonesiamemilikilebihdari700bahasadaerah,denganbahasaJawa,Sunda,Batakdigunakanpuluhanjutaorangsetiaphari.Membangun ...



Daftar isi
Bahasa Daerah dan Chatbot AI: Tantangan Unik Pasar Indonesia
Indonesia memiliki lebih dari 700 bahasa daerah, dengan bahasa Jawa, Sunda, Batak digunakan puluhan juta orang setiap hari. Membangun chatbot AI yang dapat memahami bahasa-bahasa daerah ini menghadirkan tantangan teknis yang unik. Artikel ini akan membahas solusi NLP untuk adaptasi bahasa daerah.
1. Realitas Multibahasa dan Multietnis di Indonesia
Indonesia adalah negara dengan populasi terbesar keempat di dunia, dengan lebih dari 280 juta penduduk yang tersebar di lebih dari 17.000 pulau dan menggunakan lebih dari 700 bahasa dan dialek. Menurut data Badan Pusat Statistik, bahasa daerah dengan jumlah penutur terbanyak meliputi: Jawa (sekitar 85 juta penutur, 31% populasi), Sunda (sekitar 42 juta, 15%), Batak (sekitar 8,5 juta), Minangkabau, Bugis, dll.
Meskipun bahasa Indonesia adalah bahasa resmi dan lingua franca, dalam kehidupan sehari-hari, banyak konsumen Indonesia (terutama lansia, daerah pedesaan, atau situasi informal) lebih nyaman menggunakan bahasa daerah. Penelitian menunjukkan bahwa melayani pelanggan dalam bahasa ibu atau dialek yang mereka kenal secara signifikan meningkatkan kepuasan dan kepercayaan pelanggan. Dalam skenario seperti konsultasi e-commerce, layanan pelanggan perbankan, layanan pemerintah, chatbot AI yang tidak dapat memahami atau mengenali aksen bahasa daerah akan menyebabkan banyak pelanggan beralih atau mengeluh.
Sayangnya, sebagian besar chatbot AI komersial hanya mendukung bahasa Indonesia, dengan kemampuan sangat terbatas dalam mengenali dan memahami bahasa daerah. Ini merupakan hambatan lokalisasi yang unik bagi adopsi AI customer service di pasar Indonesia.

2. Tantangan Teknis NLP untuk Bahasa Daerah
Membangun chatbot AI yang mendukung bahasa daerah Indonesia menghadapi tantangan teknis berikut:
Kelangkaan data. Model pemrosesan bahasa alami (NLP) mainstream (seperti GPT, BERT) membutuhkan data beranotasi dalam jumlah besar untuk pelatihan. Untuk bahasa Indonesia, korpus sumber terbuka yang tersedia relatif terbatas; untuk bahasa daerah seperti Jawa, Sunda, hampir tidak ada set data beranotasi berskala besar dan berkualitas tinggi. Ini membuat pelatihan model bahasa daerah dari awal sangat mahal.
Perbedaan struktur bahasa. Bahasa Jawa memiliki tingkatan kesopanan yang rumit (ngoko, krama, krama inggil). Lawan bicara dengan status sosial berbeda menggunakan kosakata dan tata bahasa yang berbeda. Model AI tidak hanya harus memahami semantik tetapi juga mengenali tingkat kesopanan yang tepat, karena kesalahan dapat dianggap "tidak sopan". Bahasa Sunda, Batak juga memiliki struktur tata bahasa dan kosakata yang unik.
Ketidakkonsistenan ejaan dan pengucapan. Banyak bahasa daerah tidak memiliki bentuk tulisan standar, ejaan dalam penggunaan sehari-hari sering sembarangan. Misalnya, kalimat yang sama dapat dieja berbeda di berbagai daerah. Pengenalan suara (ASR) juga menghadapi tantangan besar: aksen daerah sangat berbeda dari pengucapan standar bahasa Indonesia, sehingga akurasi model ASR yang ada turun drastis.
Alih kode (code-switching). Konsumen Indonesia sering mencampur bahasa Indonesia dengan bahasa daerah, bahkan Inggris, dalam satu percakapan. Contoh: "Kula badhe order nasi goreng, pake GO-PAY ya" (Jawa + Indonesia + Inggris). Model perlu memproses banyak bahasa secara bersamaan dan memahami konteksnya.
3. Solusi: Transfer Learning, Korpus Lokal, Pendekatan Hybrid
Menghadapi tantangan di atas, industri telah mengembangkan berbagai solusi:
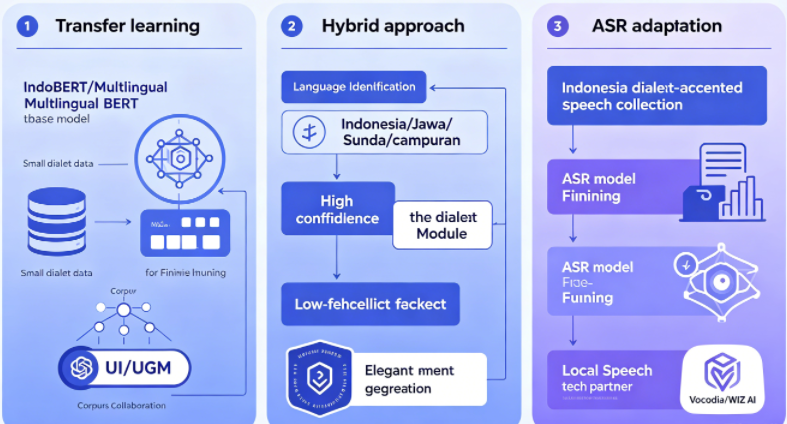
Transfer learning. Gunakan model pra-latih bahasa Indonesia sebagai basis, kemudian fine-tuning dengan sejumlah kecil data bahasa daerah beranotasi. Metode ini tidak memerlukan pelatihan dari awal, secara drastis mengurangi kebutuhan data. Misalnya, gunakan IndoBERT atau Multilingual BERT sebagai dasar, tambahkan ribuan contoh percakapan bahasa Jawa untuk fine-tuning, maka akan diperoleh kemampuan pemahaman bahasa daerah dasar.
Membangun korpus lokal. Perusahaan bekerja sama dengan institusi akademik untuk mengumpulkan sampel bahasa daerah dari percakapan layanan pelanggan nyata, anonimkan, lalu gunakan untuk pelatihan. Universitas Indonesia (UI) dan Universitas Gadjah Mada (UGM) telah memiliki proyek penelitian terkait yang berfokus pada pembangunan korpus bahasa Jawa dan Sunda. Perusahaan juga dapat memperoleh data percakapan bahasa daerah yang telah dianonimkan melalui kerja sama dengan BPO lokal.
Pendekatan hybrid. Jika tidak dapat mendukung bahasa daerah secara sempurna, gunakan strategi "identifikasi bahasa terlebih dahulu, lalu alirkan". Langkah 1: gunakan model identifikasi bahasa ringan untuk menentukan bahasa input pengguna (Indonesia/Jawa/Sunda/campuran). Langkah 2: jika teridentifikasi sebagai bahasa daerah dengan skor kepercayaan tinggi, panggil modul pemahaman bahasa daerah yang sesuai; jika skor kepercayaan rendah atau model tidak mendukung, lakukan fallback gracefully ke model bahasa Indonesia atau langsung transfer ke agen manusia. Tetapkan mekanisme jaring pengaman transfer ke manusia yang jelas untuk menghindari pelanggan beralih karena robot tidak mengerti bahasa daerah.
Adaptasi ASR untuk aksen daerah. Untuk voicebot, kumpulkan data suara bahasa Indonesia dengan aksen daerah untuk fine-tuning model ASR. Misalnya, bahkan jika pelanggan berbicara bahasa Indonesia dengan aksen Jawa, robot harus dapat mengenalinya dengan akurat. Pertimbangkan kerja sama dengan perusahaan teknologi suara lokal Indonesia (seperti Vocodia, WIZ AI).
4. Strategi Inklusif untuk Bisnis
Bagi bisnis Indonesia, mendukung semua bahasa daerah secara penuh tidak realistis dan tidak perlu. Disarankan strategi inklusif bertahap:
Langkah 1: Identifikasi bahasa daerah utama dari kelompok pelanggan inti. Jika bisnis Anda terpusat di Pulau Jawa (Jakarta, Surabaya, Yogyakarta), bahasa Jawa adalah prioritas; jika terpusat di Jawa Barat (Bandung), bahasa Sunda lebih penting. Analisis data historis layanan pelanggan untuk menentukan bahasa daerah yang paling sering digunakan pelanggan.
Langkah 2: Prioritaskan dukungan pengenalan suara (bukan teks) untuk bahasa daerah. Karena banyak penutur bahasa daerah lebih nyaman berbicara daripada menulis. Terapkan voicebot yang dapat mengenali bahasa Indonesia beraksen daerah, sehingga pelanggan dapat mengucapkan kebutuhan dengan aksen mereka, AI mengubahnya menjadi teks bahasa Indonesia standar untuk diproses.
Langkah 3: Tetapkan jaring pengaman transfer ke manusia yang jelas untuk bahasa daerah. Ketika robot mengenali bahwa pengguna menggunakan bahasa daerah dan tidak dapat memahaminya, secara proaktif beri tahu "Maaf, saya sedang belajar bahasa Jawa. Silakan beralih ke agen manusia." Ini jauh lebih baik daripada memaksakan pemahaman dan memberikan jawaban yang salah.
Langkah 4: Kerja sama dengan institusi akademik lokal untuk secara bertahap mengumpulkan korpus bahasa daerah. Investasikan anggaran kecil untuk mendukung proyek penelitian NLP di universitas lokal, Anda akan mendapatkan korpus awal dan prototipe model, sekaligus membangun citra tanggung jawab sosial perusahaan.
5. Rekomendasi Vendor & Riset Lokal
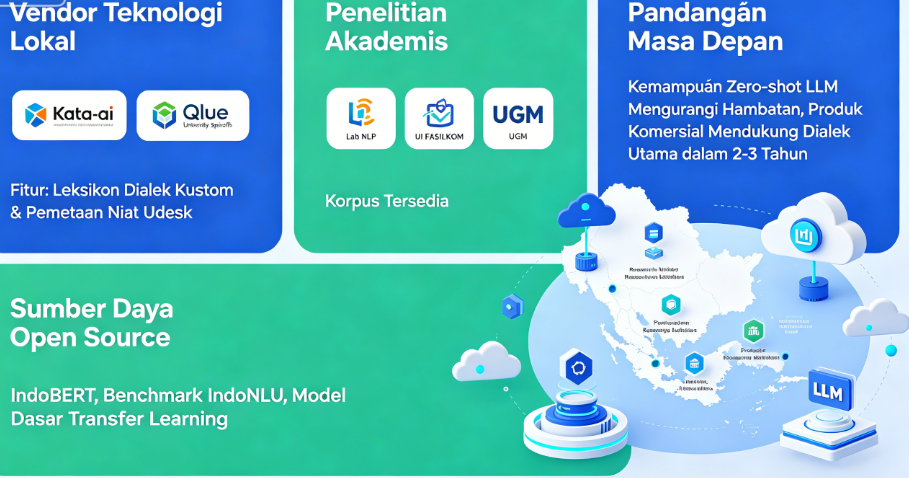
Vendor teknologi lokal. Saat ini, beberapa vendor yang memiliki akumulasi di bidang NLP bahasa daerah Indonesia antara lain: Kata.ai , Qlue (asisten suara untuk kota pintar), serta startup turunan universitas. Bagi perusahaan Indonesia yang menginginkan AI customer service omnichannel terpadu, Udesk menyediakan kerangka kerja multi-bahasa yang memungkinkan penyesuaian leksikon bahasa daerah dan pemetaan intent secara manual, sehingga dengan konfigurasi sinonim dan pola kalimat umum bahasa daerah, dapat dicapai kemampuan pemahaman bahasa daerah dasar.
Sumber daya penelitian akademik. Fakultas Ilmu Komputer UI memiliki laboratorium NLP yang fokus pada penelitian bahasa Indonesia dan bahasa daerah. Jurusan Ilmu Komputer UGM juga memiliki proyek terkait. Perusahaan dapat menghubungi lembaga ini untuk mendapatkan korpus yang telah dipublikasikan atau peluang kerja sama penelitian.
Sumber daya sumber terbuka. Saat ini tersedia model pra-latih bahasa Indonesia sumber terbuka seperti IndoBERT, tolok ukur evaluasi IndoNLU. Meskipun tidak ada model khusus untuk bahasa daerah, model ini dapat digunakan sebagai dasar untuk transfer learning.
Prospek masa depan. Dengan perkembangan model bahasa besar (LLM), kemampuan zero-shot learning menurunkan hambatan pemahaman bahasa daerah. Dalam 2–3 tahun ke depan, kemungkinan besar kita akan melihat produk AI customer service komersial yang mendukung bahasa daerah utama Indonesia.
FAQ
1. Apa perbedaan antara bahasa Indonesia dan bahasa Jawa dalam pemrosesan NLP?
Bahasa Indonesia adalah bahasa yang relatif "muda", dengan tata bahasa sederhana dan kosakata terbatas, sehingga mudah diproses NLP. Bahasa Jawa memiliki sejarah panjang, kosakata kaya, dan sistem tingkatan kesopanan yang kompleks (ngoko tingkat rendah, krama tingkat menengah, krama inggil tingkat tertinggi). Makna yang sama dapat menggunakan kosakata berbeda dalam konteks sosial yang berbeda, ini membawa tantangan besar bagi pengenalan intent NLP.
2. Apakah saya perlu mendukung semua bahasa daerah di Indonesia? Tidak. Analisis data pelanggan Anda, tentukan 2–3 bahasa daerah yang paling banyak digunakan oleh kelompok pelanggan Anda. Misalnya, merek nasional mungkin perlu mendukung bahasa Jawa dan Sunda; merek lokal cukup mendukung bahasa daerah utama setempat. Tetapkan jaring pengaman transfer ke manusia yang jelas untuk menangani kebutuhan bahasa daerah minoritas.
3. Berapa banyak data yang diperlukan untuk pelatihan model NLP bahasa daerah?
Dengan metode transfer learning, beberapa ribu hingga puluhan ribu data beranotasi sudah cukup untuk mendapatkan model dasar yang dapat digunakan. Untuk pelatihan dari awal, diperlukan ratusan ribu data. Disarankan memulai dengan transfer learning, lalu secara bertahap mengumpulkan data seiring perkembangan bisnis.
Jawab pertanyaan pelanggan 24/7 tanpa henti dengan Chatbot AI Udesk. Coba gratis dan kurangi beban manual tim CS!

Artikel ini merupakan karya asli Udesk. Jika akan diterbitkan ulang, wajib selalu mencantumkan sumber aslinya:https://id.udeskglobal.com/blog/bahasa-daerah-dan-chatbot-ai-tantangan-unik-pasar-indonesia
chatbot AI Indonesiachatbot bahasa daerah IndonesiaNLP bahasa Indonesia chatbot
